
Segmentation > Advanced > Find Text
Finds text in the Current Image using optical character recognition (OCR) [1] and places boxes around each detected word.
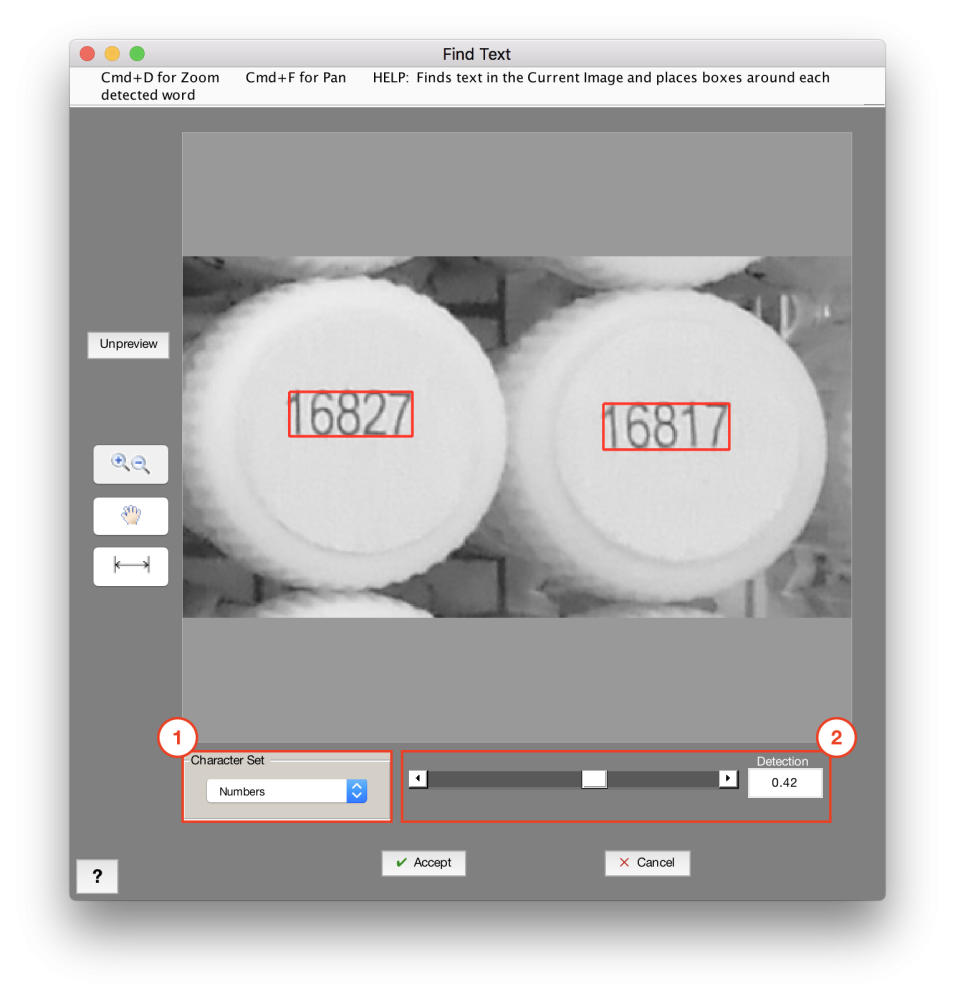
1. Character Set
Specifies the type of characters searched for
- All: Searches for all English characters
- Numbers: Searches for numbers only
2. Detection
Controls the minimum acceptable confidence of detected text. Increase the slider to increase the sensitivity of the text detection algorithm. (Recommended: 0.5)
References
[1] R. Smith. An Overview of the Tesseract OCR Engine, Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007) Vol 2 (2007), pp. 629-633.
Need more help with this?
Chat with an expert now ››
Copyright © 2025 MIPAR
—
Powered by 