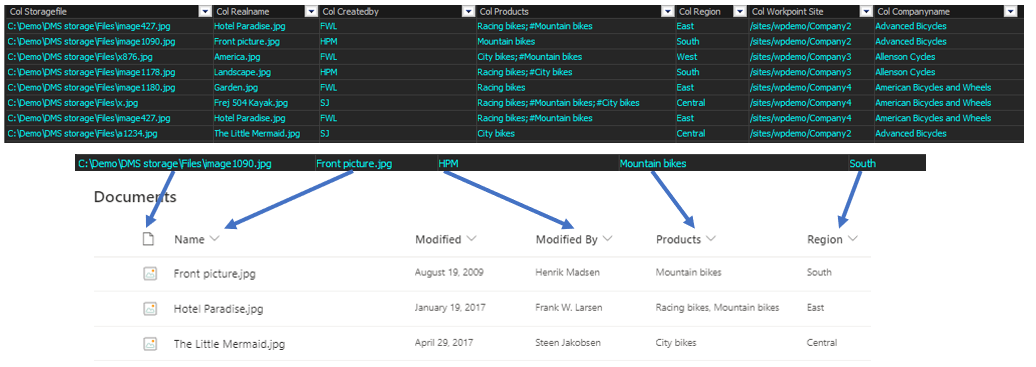
Bespoke “file distribution driver”. Any data source can define the source & destination structures and drive the migration instead of the current storage location in a FileShare or SharePoint Library
This is a fundamental change in the way you approach and execute migration to SharePoint.
| The essence of “data-driven file distribution” |
- The file selection process is driven by a data set from any data source
|
- You can “cherry-pick” files from multiple storage locations or from one big pile of files in FileShares or SharePoint document libraries.
|
- The metadata for the files can be extracted from any data source. Data staging enables comprehensive data cleansing and transformation.
|
- The data sets that drive the migration or defines the metadata can be constructed with nocode using state of the art Migration Automation for data transformation thereby enabling migration from any content management system.
|
| SMART Migration For SharePoint is designed for |
| |
- Simplifying high complexity migration projects
|
- Inclusion of major/minor version history – transform multiple files into SharePoint document library item with version history
|
- BI Tracking and reporting for each and every file
|
Data sources include: ![]()
![]()
![]()
![]()
![]()
![]()
![]()
For-Each row in the “driver data set” migrate the file with associated metadata to SharePoint
*The metadata columns [Filename], [Created], [Modified] can also be part of the “driver data set” so the physical file is just an anonymous binary container file without any metadata. Also, any document attribute within the file can be extracted and used for metadata.
Last modified:
23 November 2023