
Neben der manuellen Erfassung von einzelnen Datensätzen kann ein große Anzahl von Datensätzen über CSV Dateien importiert werden.
Zum leichten Verstehen der CSV-Import-Schnittstelle wird im folgenden als Beispiel die Vorgehensweise beim Import von Adressen gezeigt. Beim Import Ihrer Datensätze müssen Sie die Datenfelder und Spalten entsprechend anpassen.
Fallbeispiel Adressen
In diesem Beispiel wird eine Adressdatei als Beispiel gewählt, die häufig für einen Import vorgefunden wird. In der ersten Zeile sind die Spaltentitel enthalten. Jede weitere Zeile enthält sowohl die Daten einer Firma, also auch die eines Kontaktes innerhalb der Firma. Die Datei hat folgenden Aufbau:


Welche Daten sind in einer Importzeile?
Eine Zeile der Importdatei beinhaltet Stammdaten von Firmen und Kontakten, Anschriften und Kommunikationsdaten. Durch die Datenstruktur der Zielanwendung (also die Anwendung in der die Datensätze importiert werden sollen) ist vorgegeben, dass diese Datensätze auf mehrere (gewöhnlich normalisierte – aufgeteilte) Datentabellen und Teildatentabellen verteilt gespeichert werden müssen. Zusammengehörende Daten sind dabei über eine Relation miteinander verknüpft. Beispiel: Eine Firma hat viele Mitarbeiter.
Daher ist es zuerst notwendig, diese aufgeteilten Datentabellen in der Zielanwendung herauszufinden. Jede Spalte der Importdatei ist dabei einzeln zu betrachten und zu einem Datenfeld einer Datentabelle der Zielanwendung zuzuordnen.
Das Ergebnis der Zuordnung von Spaltentitel zu den Datenfeldern obiger Adressdatei ergibt folgende Tabelle:
| Datensätze der Importdatei | (Teil-)Datentabelle der Zielanwendung | Spaltentitel der Importdatei | Datenfeld in Datentabelle der Zielanwendung |
|---|---|---|---|
| Firma | Company | Company, Website | Name, Website |
| Kontakt | Contact | Salutation, Firstname, Lastname, Title, Function, Department | Salutation, FirstName, LastName, Titles, ContactFunction, Department |
| Anschrift | Contact.Addresses / Company.Addresses | Street, Zip, City, Country | Address, PostalCode, City, Country |
| Kommunikation | Communication | Phone | ID |
| Contact.Emailaddresses / Company.Emailaddresses | EmailAddress |
Jeder Zeile der obigen Tabelle entspricht dabei einer (Teil-)Datentabelle in der Zielanwendung, in die Daten eingelesen werden müssen. Für jede (Teil-)Datentabelle in Ihrer Zielanwendung wird eine Importdatei benötigt. Somit ist es notwendig die erhaltenen Importdatei des Fallbeispiel in mehrere Dateien aufzuteilen.
Schritt 1: Anpassen der Spaltentitel
Der Spaltentitel hat beim Import eine besondere Funktion, denn er bestimmt das Datenfeld in das importiert wird. Daher sind nun in der Importdatei diejenigen Spaltentitel, die vom Namen des Datenfeldes abweichen, auf den vorgegebenen Namen des Datenfeldes der Zielanwendung umzubenennen.
Folgende Spaltentitel werden von dem erhaltenen Namen zum vorgegebenen Namen umbenannt:
| Spaltentitel (alt) | Spaltentitel (neu) |
|---|---|
| Company | Name |
| Firstname | FirstName |
| Lastname | LastName |
| Title | Titles |
| Function | ContactFunction |
| Street | Address |
| Zip | PostalCode |
| Phone | ID |
| EmailAddress |
Die Importdatei hat nun folgendes Aussehen:


Schritt 2: Eindeutiger Importschlüssel für Firmen
Jeder zu importierende Datensatz muss einen eindeutigen Importschlüssel besitzen. Dies ist notwendig, damit der Datensatz
- eindeutig identifiziert werden kann.
- bei einem erneuten Import, nicht doppelt angelegt wird.
- über den Importschlüssel mit anderen Datensätzen verknüpft werden kann.
Damit beim Import eines Kontaktes dieser auch mit einer Firma verknüpft werden kann, ist es notwendig, dass für jede zu importierende Firma ein eindeutiger Importschlüssel vergeben wird. Als Importschlüssel empfiehlt es sich, einen fixen, den Datensatz beschreibenden Text, gefolgt von einer fortlaufenden Nummer zu verwenden.
Dazu wird als erste Spalte der Importdatei eine neue Spalte mit dem Namen “MigrationID” ergänzt. Die Zellen der neuen Spalte “MigrationID” sind anschließend mit einem eindeutigen Importschlüssel für die jeweilige Firma zu befüllen, z.B. Comp000001, Comp000002, …
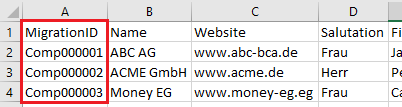
Schritt 3: Erstellen der Importdatei für Firmen und Kontakte
Durch Duplizieren der Importdatei wird zunächst eine Importdatei für Firmen und eine für Kontakte erstellt.
1) Importdatei Firmen
Aus der Importdatei der Firmen werden nun alle kontaktspezifischen Spalten entfernt, da diese mit der zweiten Importdatei “Kontakte” verarbeitet werden.
Folgende Spalten werden entfernt: Salutation, FirstName, LastName, Titles, ContactFunction, Department, ID, EmailAddress
Die Importdatei für Firmen hat nun folgendes Aussehen:

2) Importdatei Kontakte
Aus der Importdatei der Kontakte werden anschließend alle firmenspezifischen Spalten entfernt.
Folgende Spalten werden entfernt: Name, Website
Die Importdatei für Kontakte hat nun folgendes Aussehen:


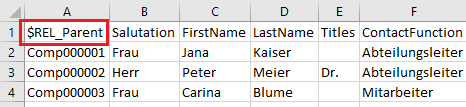
Schritt 4: Kontakte mit Firma verknüpfen
Die Verknüpfung von Datensätzen (in diesem Beispiel also eine Firma mit einem oder mehreren Kontakten) erfolgt über Relationen. Aus der Datenstruktur der Zielanwendung ergibt sich, dass ein Kontakt mit einer Firma über die Relation “Parent” verknüpft ist. In der Importdatei der Kontakte ist daher eine Verknüpfungsspalte zu ergänzen. Der Kontakt muss wissen zu welcher Firma er gehört. Der Spaltentitel einer Verknüpfungsspalte beginnt immer mit dem fixen Text “$REL_”, gefolgt vom Namen der Relation. Die Spalte beinhaltet den eindeutigen Importschlüssel des zu verknüpfenden Firmen-Datensatzes. Im Fallbeispiel ist es ausreichend den Spaltentitel der Spalte “MigrationID” in “$REL_Parent” umzubenennen, da die Zellen der Spalte bereits den Importschlüssel der Firma beinhalten.
Die Importdatei für Kontakte hat nun folgendes Aussehen:
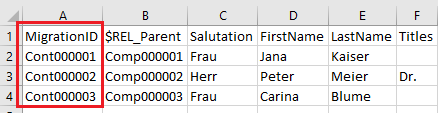
Schritt 5: Eindeutiger Importschlüssel für Kontakte
Für die zu importierenden Kontakte muss nun ebenfalls ein eindeutiger Importschlüssel vergeben werden, damit er später mit weiteren Daten (wie Telefonnummern oder Anschriften) verknüpft werden kann. Dazu wird als erste Spalte der Importdatei der Kontakte eine neue Spalte mit dem Namen “MigrationID” ergänzt. Die Zellen der neuen Spalte “MigrationID” sind anschließend mit einem eindeutigen Importschlüssel für den jeweiligen Kontakt zu befüllen, z.B. Cont000001, Cont000002, …
Schritt 6: Anschriften
Die Datenstruktur der Zielanwendung sieht eine eigene Teildatentabelle zur Speicherung der Anschrift einer Firma bzw. eines Kontaktes vor. Eine Anschrift besteht dabei u.a. aus Straße, Postleitzahl und Ort. Die Daten der Anschrift sind daher aus den beiden Importdateien für Firmen und Kontakte in eine eigene Importdatei für Anschriften auszulagern und mit der jeweiligen Firma bzw. dem jeweiligen Kontakt über die Angabe der ParentId zu verknüpfen.
Für das Fallbeispiel sind folgende Schritte durchzuführen:
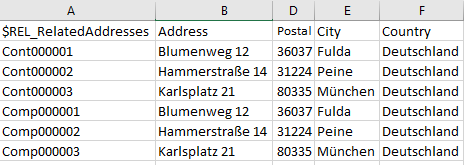
1) Erstellung der Importdateien für die Teildatentabellen der Anschriften
Die Importdateien für die Anschriften haben für Firmen und Kontakte die gleiche Struktur. Sie benötigen folgende Spalten: ParentId, AddressType, Address, PostalCode, City und Country.
Der Name der Importdatei für Anschriften der Firmen lautet “ Company.Addresses”, der für die Importdatei für Anschriften der Kontakte “ Contact.Addresses”.
In der folgenden Tabelle ist beschrieben, was die Spalten beinhalten und aus welchen Spalten der Importdateien für Firmen und Kontakte diese zu übernehmen (kopieren) sind.
| Spaltentitel der neuen Datei | Beschreibung | Spalteninhalt kopieren aus Spalte |
|---|---|---|
| ParentId | Importschlüssel der Firma / des Kontaktes zur Verknüpfung mit der Anschrift | MigrationID |
| AddressType | Typ der Anschrift | In allen Zeilen fester Wert: “Hauptanschrift” |
| Address | Adresse der Anschrift | Address |
| Zip | Postleitzahl der Anschrift | Zip |
| City | Ort der Anschrift | City |
| Country | Land der Anschrift | Country |
Die Zuweisung des festen Wertes “Hauptanschrift” als Anschriftentyp sorgt dafür, dass diese Anschrift vom System als Primäranschrift verwendet wird.
Die Importdatei für Anschriften hat nun folgendes Aussehen und Inhalt:
2) Entfernen von Spalten
Nach der Übernahme der Spalten Address, PostalCode, City und Country in die Importdateien der Anschriften, werden diese in den Importdateien für Firmen und Kontakte nicht mehr benötigt und sind zu entfernen.
Die Importdatei für Firmen hat nun folgendes Aussehen:
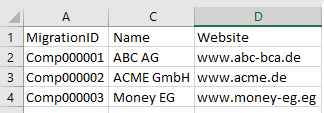
Die Importdatei für Kontakte hat nun folgendes Aussehen:
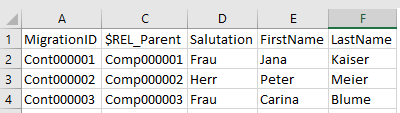

Schritt 7: E-Mail-Adressen
Die Datenstruktur der Zielanwendung sieht eine eigene Teildatentabelle zur Speicherung der E-Mail-Adresse einer Firma bzw. eines Kontaktes vor. Eine E-Mail-Adresse besteht dabei aus der E-Mail-Adresse selbst. Die Daten der E-Mail-Adresse sind daher aus den beiden Importdateien für Firmen und Kontakte in eigene Importdateien für E-Mail-Adressen auszulagern und mit der jeweiligen Firma bzw. dem jeweiligen Kontakt über die Angabe der ParentId zu verknüpfen.
Für das Fallbeispiel sind im Kontext E-Mail sinngemäß die selben Schritte wie für die Anschriften durchzuführen:
Schritt 8: Kommunikationsdaten
Die Datenstruktur der Zielanwendung sieht eine eigene Datentabelle zur Speicherung der Kommunikationsdaten von Firmen und Kontakten vor. Zu den Kommunikationsdaten zählen unter anderem Telefonnummern, Mobilnummern oder auch Faxnummern. Im Fallbeispiel hat nur die Importdatei der Kontakte eine Spalte mit einer Telefonnummer. Diese ist nun in eine eigene Importdatei für Kommunikationsdaten auszulagern und mit dem jeweiligen Kontakt über eine Relation zu verknüpfen. In der Zielanwendung können pro Firma oder Kontakt mehrere Kommunikationsdaten vorhanden sein. Eine dieser Kommunikationsdaten kann dabei als primäre gekennzeichnet werden.
Für das Fallbeispiel sind folgende Schritte durchzuführen:
1) eindeutigen primären Kommunikationsdaten-Schlüssel für Kontakte vergeben
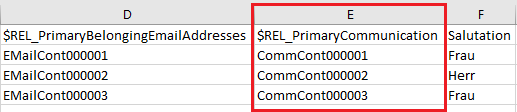
Dazu wird in der Importdatei für Kontakte eine neue Spalte mit dem Namen “$REL_PrimaryCommunication” ergänzt. Die Zellen der neuen Spalte “$REL_PrimaryCommunication” sind anschließend mit einem eindeutigen Importschlüssel für die Kommunikationsinformation des Kontaktes zu befüllen, z.B. CommCont000001, CommCont000002, …
Die ergänzte Spalte hat folgendes Aussehen:
2) Erstellung der Importdatei für Kommunikationsdaten
Die Importdatei der Kommunikationsdaten benötigt folgende Spalten: MigrationID, $REL_Communication, TypeOfCommunication, ID. In der folgenden Tabelle ist beschrieben, was die Spalten beinhalten und aus welchen Spalten der Importdatei für Kontakte diese zu übernehmen sind.
| Spaltentitel der neuen Datei | Beschreibung | Spalteninhalt kopieren aus Spalte |
|---|---|---|
| MigrationID | eindeutiger Importschlüssel der Kommunikationsinformation | $REL_PrimaryCommunication |
| $REL_Communication | Importschlüssel des Kontaktes zur Verknüpfung mit der Kommunikationsinformation | MigrationID |
| TypeOfEmail | fixer Text, z.B. ‘Telefon (geschäftlich)’ oder ‘Mobil’ | |
| ID | Telefonummer, Mobilnummer, Faxnummer | ID |
Die Importdatei für Kommunikationsdaten hat nun folgendes Aussehen und Inhalt:

3) Entfernen von Spalten
Nach der Übernahme der Spalte ID in die Importdatei der Kommunikationsdaten, wird diese in der Importdatei für Kontakte nicht mehr benötigt und ist zu entfernen.
Die Importdatei für Kontakte hat nun folgendes Aussehen:


Schritt 9: Dateinamen
Zuletzt ist es notwendig die Importdateien korrekt zu benennen, da durch den Namen der Importdatei die Importreihenfolge und die Datentabelle der Zielanwendung festgelegt wird.
Folgende Namen sind zu vergeben:
| Importdatei | Dateiname |
|---|---|
| Firmen | 001 OrmCompany.csv |
| Firmen-Anschriften | 002 OrmCompany.Addresses.csv |
| Firmen-E-Mail-Adressen | 003 OrmCompany.Emailaddresses.csv |
| Kontakte | 004 OrmContact.csv |
| Kontakt-Anschriften | 005 OrmContact.Addresses.csv |
| Kontakt-E-Mail-Adressen | 006 OrmContact.Emailaddresses.csv |
| Kommunikationsdaten | 007 OrmCommunication.csv |
Geschafft: Die zu importierende Datei wurde in die Datenstruktur der Zielanwendung umgebaut. Alle Teildatensätze und Relationen sind nunmehr in eigenen CSV Dateien und können importiert werden.
Wichtig: Alle CSV Dateien müssen im UTF-8 Format gespeichert werden und Zeilenumbrüche richtig sein. Sind hier Fehler, so funktioniert der Import nicht.
Detaillierte Information im Kapitel Importkonfiguration verwalten.